한결과 레지아이스
선형 자료구조 - 배열과 연결 리스트 본문
자료구조는 선형과 비선형으로 나뉜다. 하나의 자료 뒤에 하나의 자료가 위치하면, 관계가 1:1이면 선형 자료구조라고 한다. 하나의 자료 뒤에 n개의 자료가 위치하면, 관계가 1:n 혹은 n:n이라면 비선형 자료구조라고 한다.
선형 자료구조에는 배열, (연결)리스트, 스택, 큐 등이 있고 비선형 자료구조에는 트리와 그래프 등이 있다. 배열과 연결 리스트부터 스터디는 시작된다.
배열 (Array)
배열은 데이터가 메모리상에 연속적으로, 순서대로 저장된다. 자료의 크기가 같아야 하고, 이런 특성들 덕분에 시작 메모리 주소에 인덱스를 더해서 바로 접근할 수 있다. 그래서 자료의 조회가 바로 빠르다.

크기는 처음에 할당 받은 대로 한정된다. arr[100]으로 선언했다면 이 배열의 크기는 계속해서 100이다. 크기를 유동적으로 사용하려면 동적 할당을 사용하고 메모리 해제 후 재할당 하는 등의 번거로운 과정을 거쳐야 한다.
데이터들이 메모리에 연속적으로 존재해야 하기 때문에, 데이터가 삽입되거나 삭제될 때 배열의 맨 끝에서 일어나는 경우를 제외하면 간단하지 않아진다. 중간에 삽입하는 경우, 기준점 뒤의 데이터들을 한 데이터 만큼 뒤로 밀어주어야 한다. 맨 앞에 삽입하는 경우, 모든 데이터를 한 칸 밀어줘야 하기 때문에 O(N)의 시간복잡도가 생긴다.
삭제의 경우도 똑같다. 중간에서 삭제가 일어나는 경우, 빈 공간이 없도록 삭제된 데이터 이후를 모두 당겨줘야 한다. 맨 앞에서 삭제가 일어나면, 모든 데이터를 한 칸 앞으로 당기게 된다. 근데 왜 빈 공간이 존재하면 안되는가?

빈 공간이 있으면 배열은 의미를 잃는다. 데이터가 5개 있는 배열을 상상해보자. 나는 그 중 2 번째, 가운데의 데이터를 제거했다. 그러면 배열에는 데이터가 4개가 남아있고, 0, 1, 3, 4번째 칸에 데이터가 들어있다. 근데 이렇게 남은 데이터에 반복문을 이용하거나 하면 어떻게 될까?
int arr[5] = {1, 2, 3, 4, 5};
remove arr[2]; // 어떻게든 못쓰게 되었다고 생각해보자.
for (int i = 0; i < 4; i++) {
doSomething(arr[i]);
}
// doSomething(arr[0]),
// doSomething(arr[1]),
// doSomething(arr[2]) -> 여기서 문제가 생긴다
// doSomething(arr[3]) -> 여기서 반복문이 끝난다.
그럼 arr[4]는?? 사실 arr[2]가 생략되고 arr[4]까지 반복되어야 하는데, 5개 중에 데이터 1개가 빠진 경우라 반복문을 쉽게 조정할 수 있겠지만 데이터의 규모가 커지고 빠진 데이터의 개수도 늘어난다고 생각해보자. 문제를 피할 수 없을 것이다.
정리해보면, 배열의 단점은 다음과 같다.
- 크기가 처음 할당 받은 만큼으로 한정된다.
- 삽입과 삭제할 때 최악의 경우 모든 데이터를 이동시켜야 한다.
그렇다면 장점은?
- 조회가 빠르다.
- 저장공간의 효율이 매우 좋다. (데이터 자체 이외의 정보가 필요하지 않다)
연결 리스트(Linked List)
문제가 복잡해지기 시작한다. 노드가 나오고 링크가 나오고 기승을 부리기 시작한다. 하지만 천천히 보면 쉽다. 오래 보면 사랑스럽다.
각 데이터는 하나의 노드로 이루어진다. 노드 안에는 데이터가 들어있고, 다음 노드를 가리키는 포인터도 들어있다. 나라는 노드는 다음 노드의 주소를 알고있다. 다음 노드는 그 다음 노드의 주소를 알고있다. 줄줄이 사탕처럼 엮여있다.

하지만 일종의 점조직이라, 나는 내 앞을 모른다. 다만 다음을 알 뿐. 그래서 시작 노드의 주소만 알고 있다면, 점점점 나아가서 마지막까지 갈 수 있다. 마지막 노드는 다음 노드로 NULL을 가리킨다. 더 이상 갈 곳이 없다는 뜻이다. 연결 리스트는 이렇게 이루어진다.
각각의 데이터는 연속되어있지 않다! 배열과는 큰 차이이다. 삽입, 삭제, 조회에서도 차이가 난다. 어떻게 다른지 알아보자.
삽입을 먼저 알아보면, 배열에 비해 굉장히 단순해졌다. 삽입될 자리의 앞 노드를 <front>, 뒷 노드를 <rear>, 삽입되는 노드를 <me>라고 생각해보자. front는 현재 rear를 가리킨다. rear가 뭘 가리키는지는 중요하지 않다. front가 me를 가리키고, me는 rear를 가리키게 된다면? me는 완벽하게 front와 me 사이에 위치하게 된다. 메모리상의 주소가 실제로 그 사이에 있는지는 중요하지 않다. 연결이 중요하다.
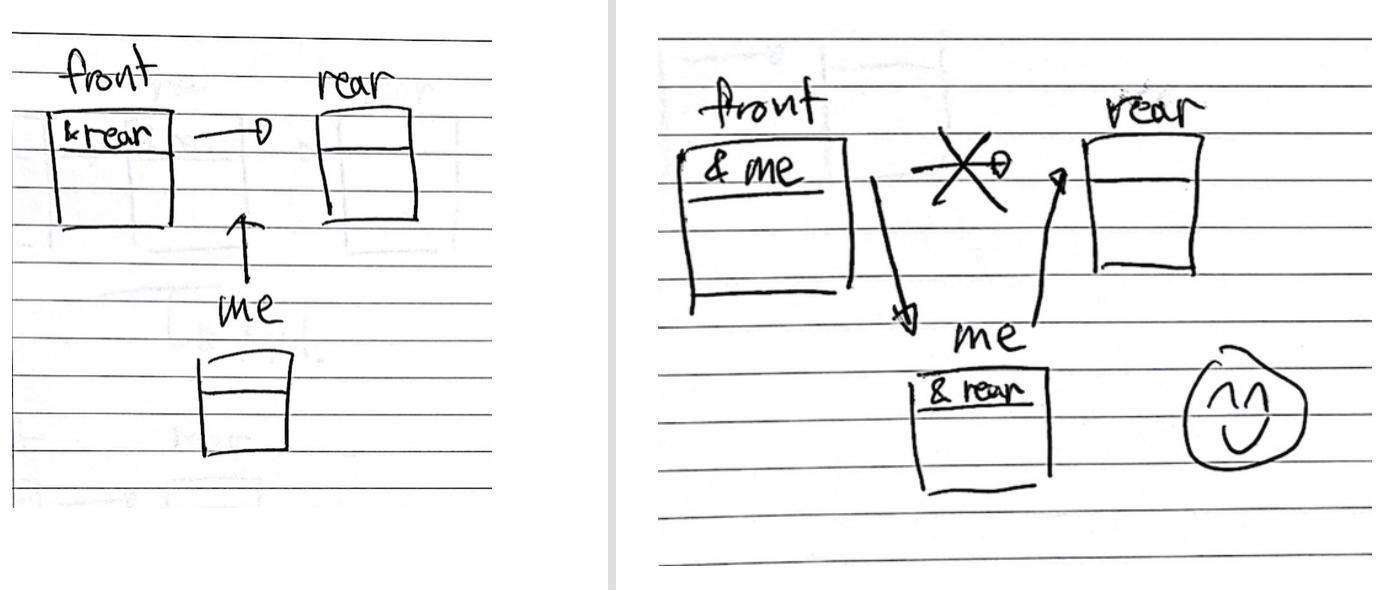
삭제도 간단하다. 앞선 예시와 똑같이 삭제될 자리의 앞 노드를 <front>, 뒷 노드를 <rear>, 삭제되는 노드를 <me>라고 생각해보자. 지금은 front가 me를, me가 rear를 가리키고 있다. 삽입되기 전으로 되돌려주면 된다! front가 가리키고 있는 me의 자리에, me가 가리키는 rear를 넣어주면 된다. 그리고 me를 세상에서 사라지게 해주면 된다.
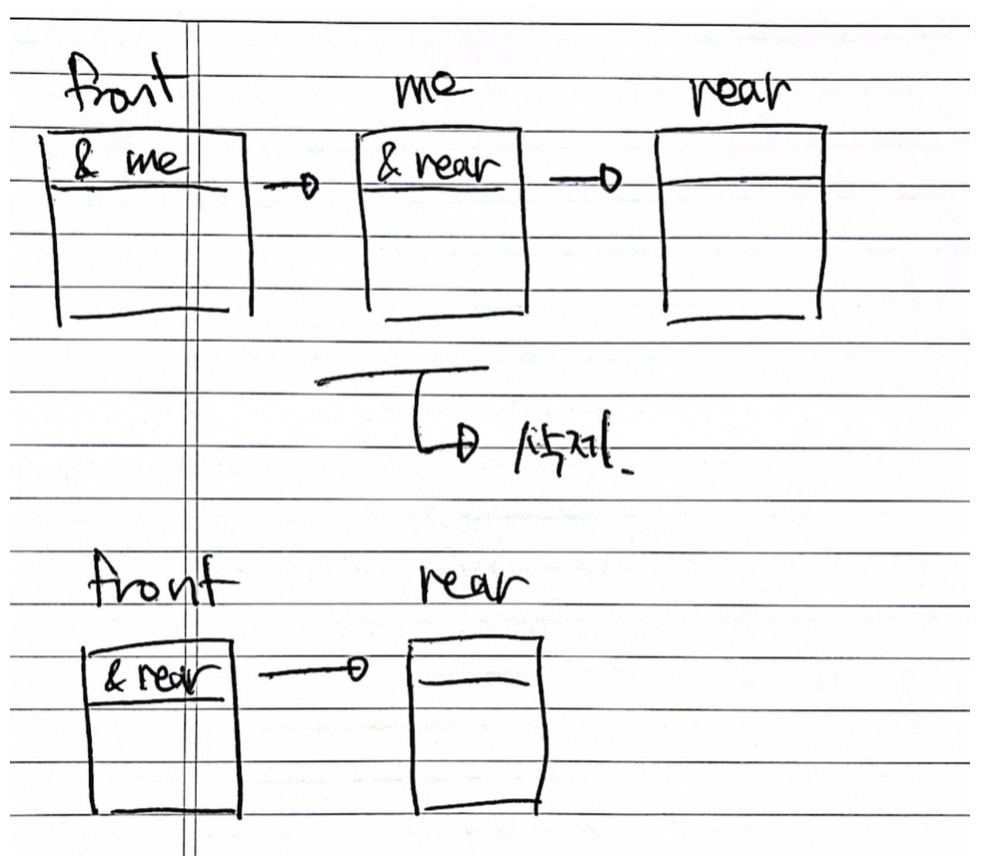
삭제나 삽입을 하려면 어디에 할지 정해야한다. 이 조회를 어떻게 하는가? 배열처럼 인덱스를 사용할 수는 없다. 연속적으로 저장되어 있지 않기 때문에 시작 주소를 알고 몇 번째 자료인지 안다고 해서 시작 주소에 인덱스를 더했을 때 해당 노드가 나오지 않는다. 조회 역시 배열과는 방법이 많이 달라진다.
그러면 어떻게 하는가? 원하는 인덱스 만큼 시작 노드부터 전진하면 된다. 100번째 자료가 필요하다, 그러면 시작 노드부터 99번 전진하면 된다. 노드가 갖고 있는 포인터로 가는 것을 전진이라고 표현해보았다.
장점은? 일단 삽입 삭제가 쉽다. 근데 삽입 삭제를 하러 가기 위해서 조회를 해야하지만… 어딘지만 알면 쉽다. 그리고 리스트의 크기가 정해져있지 않다. 배열은 100칸이다! 정해놓지만 리스트는 그냥 계속 같다 붙여도 된다(메모리가 허용하는 한까지만..).
단점은 배열과 먼저 비교해보자. 일단 배열에 비해 저장공간의 효율이 낮다. 64bit 환경으로 가정해보자. int의 배열이면 4byte(int의 크기) * 자료의 개수 만큼 저장공간을 차지한다. 연결 리스트는? (4byte + 8byte(포인터의 크기)) * 자료의 개수 만큼 저장공간을 차지한다. 데이터의 크기가 커진다면 큰 의미는 없겠지만, 지금은 저장공간을 3배나 많이 차지한다. 그리고 조회를 인덱스로 즉시 접근할 수 없고 시작 노드부터 타고 가야한다는 것도 단점이다.
내가 현재 101번째 노드를 조회 중일때 100번째 노드로 가고싶다고 생각해보자. 어떻게 돌아갈까? 정답은 ‘돌아갈 수는 없다’이다. 그러면 어떻게 가냐? 시작 노드부터 100번까지 다시 가면 된다. 비효율적이고 불합리하다. 인생에서 기회를 놓친다는 것과 유사해 보인다. 근데 놓친 기회를 다시 잡을 수 있다면 어떨까? 이전 노드로 돌아가고 싶다면? 그래서 나오는 것이 이중 연결 리스트이다.
이중 연결 리스트(Doubly Linked List)
배울 개념이 더 늘어나는 부분은 아니다. 그림 하나만 보면 된다. 아까는 다음 노드만 가리켰는데, 이제는 이전 노드를 가리킬 주소 하나 추가하면 된다.
무엇이 좋은가 하면 이제 뒤로 돌아갈 수 있기 때문에, 하나 전의 걸 찾으려고 맨 처음부터 다시 순회할 일이 없다. 노드 구조체에 이전 주소를 담을 포인터 하나만 더 들어가면 되기 때문에 따로 구현을 하지는 않고, 밑에 나오는 개념과 합쳐 이중 연결 원형 리스트로 구현했다.
원형 연결 리스트(Circular Linked List)
리스트의 마지막 노드가 NULL 대신 시작 노드를 가리키는 리스트를 말한다. 어떤 한 지점의 노드에서도 모든 노드에 접근할 수 있다. 원형이 아니고 이중이 아닌 기본 단방향 연결 리스트의 경우 시작 노드가 아니면 자신보다 앞선 노드들에 접근할 수 없음을 떠올려 볼 수 있다. 리스트의 맨 뒤에 도달한 경우, 다음 노드로 간다면 첫 번째 노드를 마주하게 된다.
마지막 노드에 접근을 용이하게 하기 위한 것이므로, 헤드 노드가 리스트의 마지막 노드를 가리키게 해야 마지막 노드에도 접근할 수 있고, 마지막의 다음 노드로 첫 번째 노드에도 쉽게 접근이 가능하다(단방향 원형 이야기).
다음 노드를 계속 가리키다 보면 끝에 닿고 그 다음이 시작이고 이러니 반복 작업에 용이하다고 한다.
연결 리스트와 헤드 노드
헤드 노드는 리스트의 시작 노드를 가리키는 노드이다. 데이터를 갖지 않아도 되는 노드이며, 오직 시작 노드를 기리키기 위해서만 존재한다. 구현에 따라 노드가 아니고 포인터로 시작 노드의 주소만 보관하기도 한다. 기존에 42서울에서 과제를 진행하며, 굳이 헤드 노드를 만들지 않고 시작 노드를 head라는 이름으로 사용했기에 헤드 노드가 왜 필요한지 의문을 가졌었다.
하지만 이번에 헤드 노드를 가진 리스트를 구현해 보면서, 삽입이나 삭제 함수에서 리스트의 시작 노드인지 등에 따라 분기가 나뉘지 않아도 된다는 점에서 편리하다고 느꼈다.
구현 코드: DataStructureStudy/Lists at main · triplecheeseburger/DataStructureStudy
'Today I Learned > Data Structure' 카테고리의 다른 글
| 선형 자료구조 - 스택 (0) | 2022.08.06 |
|---|---|
| 자료구조 스터디 기록 (0) | 2022.07.29 |
